 ALL ARTICLES
ALL ARTICLES 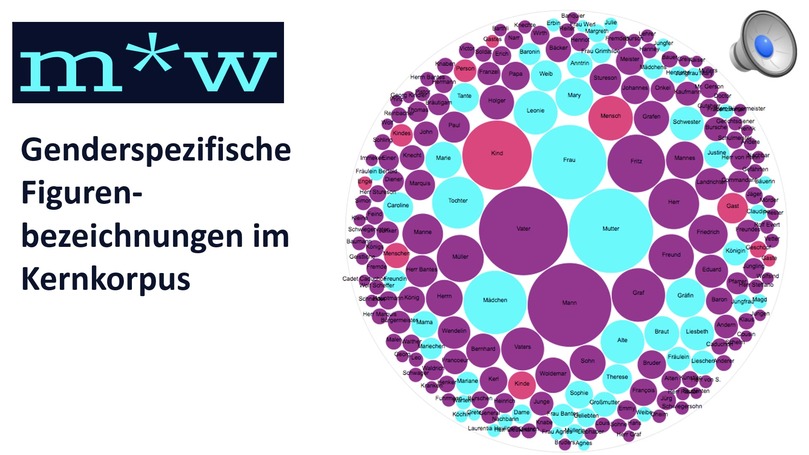


")













Im Projekt m*w untersuchen Marie Flüh und Mareike Schumacherseit Sommer 2019 Genderstereotype und -bewertungen (in Form von Emotionen) in literarischen Texten. Anstelle einer Präsentation der literatur- und kulturwissenschaftlich relevanten Erkenntnisse aus dem Projekt (die Sie hier nachlesen können), setzten sie im Rahmen des Kolloquiums einen methodischen Schwerpunkt und zeigen Perspektiven auf eine literaturwissenschaftliche Auseinandersetzung mit Named Entity Recognition und Emotion Analysis.
Im ersten Teil des Vortrags werden interessante Nebenbefunde vorgestellt, die aus den Bemühungen entstanden sind, ein Named Entity Recognition Tool so zu trainieren, dass es eine möglichst leistungsstarke automatische Annotation von weiblichen, männlichen und neutralen Figurenreferenzen erreicht. Die Wissenschaftlerinnen möchten zeigen, wie sie dabei “zufällig” zu einer Art Barometer für Texte mit besonders stereotypen Figurenreferenzierungen kamen und auf welche Art und Weise Texte ausfindig gemacht werden können, die ihrer Zeit im Hinblick auf die Darstellung von Gender voraus sind. Dabei wird die Methode der automatischen Figurenerkennung mit einigem Vergnügen gegen den Strich gebürstet. Toolbewertungsverfahren werden zum eigentlichen Hilfsmittel der Analyse und ein Scalable-Reading-Prozess setzt ein.
Im zweiten Teil des Vortrags erläutern Marie Flüh und Mareike Schumacher unterschiedliche Perspektiven auf die digitale Analyse sentimenttragender Textmerkmale in novellistischen Texten. Gerade literarische Texte gelten als hochgradig emotionales Unterfangen, wobei die Kommunikation der Figuren eines der wichtigsten Bestandteile der literarischen Emotionalisierungstechniken darstellt (Anz 2007: 219). Auf welche Art und Weise lassen sich positive und negative Emotionen in Abhängigkeit zum Geschlecht einer Figur also wieder aus literarischen Texten herausfiltern? Wie könnte ein computergestütztes Verfahren aussehen, das sowohl der Spezifik literarischer Texte gerecht wird als auch (halb)automatische Arbeitsschritte beinhaltet, die einer emotionsbezogenen Korpusanalyse mit literaturwissenschaftlichem Erkenntnisinteresse den Weg bereitet?
m*w liegt ein Mixed-Methods-Ansatz zugrunde, der methodische Anleihen bei den Sozialwissenschaften/Informationswissenschaften (Sentiment Analysis), den Literatur- und Kulturwissenschaften und Verfahren, die gegenwärtig zur digitalen Analyse von literarischen Texten in den sog. Computational Literary Studies – also: in der digitalen Literaturwissenschaft – eingesetzt werden, macht.